ه“ˆه¤«و›¼و ‘ن»‹ç»چï¼ڑ(ه¥½هگ§ï¼Œéƒ¨هˆ†copyè‡ھ百ه؛¦çں¥éپ“^_^)
ه“ˆه¤«و›¼و ‘هڈˆç§°وœ€ن¼کن؛Œهڈ‰و ‘,وک¯ن¸€ç§چه¸¦وƒè·¯ه¾„é•؟ه؛¦وœ€çںçڑ„ن؛Œهڈ‰و ‘م€‚و‰€è°“و ‘çڑ„ه¸¦وƒè·¯ه¾„é•؟ه؛¦ï¼Œه°±وک¯و ‘ن¸و‰€وœ‰çڑ„هڈ¶ç»“点çڑ„وƒه€¼ن¹کن¸ٹه…¶هˆ°و ¹ç»“点çڑ„è·¯ه¾„é•؟ه؛¦ï¼ˆè‹¥و ¹ç»“点ن¸؛0ه±‚,هڈ¶ç»“点هˆ°و ¹ç»“点çڑ„è·¯ه¾„é•؟ه؛¦ن¸؛هڈ¶ç»“点çڑ„ه±‚و•°ï¼‰م€‚و ‘çڑ„ه¸¦وƒè·¯ه¾„é•؟ه؛¦è®°ن¸؛WPL=(W1*L1+W2*L2+W3*L3+...+ Wn*Ln),Nن¸ھوƒه€¼Wi(i=1,2,...n)و„وˆگن¸€و£µوœ‰Nن¸ھهڈ¶ç»“点çڑ„ن؛Œهڈ‰و ‘,相ه؛”çڑ„هڈ¶ç»“点çڑ„è·¯ه¾„é•؟ه؛¦ن¸؛Li(i=1,2,...n)م€‚هڈ¯ن»¥è¯پوکژه“ˆه¤«و›¼و ‘çڑ„WPLوک¯وœ€ه°ڈçڑ„م€‚
هˆ©ç”¨ه“ˆه¤«و›¼ç¼–ç پè؟›è،Œé€ڑن؟،هڈ¯ن»¥ه¤§ه¤§وڈگé«کن؟،éپ“هˆ©ç”¨çژ‡ï¼Œç¼©çںن؟،وپ¯ن¼ 输و—¶é—´ï¼Œé™چن½ژن¼ 输وˆگوœ¬م€‚
1م€پè·¯ه¾„ه’Œè·¯ه¾„é•؟ه؛¦
هœ¨ن¸€و£µو ‘ن¸ï¼Œن»ژن¸€ن¸ھ结点ه¾€ن¸‹هڈ¯ن»¥è¾¾هˆ°çڑ„ه©هگوˆ–هگه™ç»“点ن¹‹é—´çڑ„é€ڑ路,称ن¸؛è·¯ه¾„م€‚é€ڑè·¯ن¸هˆ†و”¯çڑ„و•°ç›®ç§°ن¸؛è·¯ه¾„é•؟ه؛¦م€‚若规ه®ڑو ¹ç»“点çڑ„ه±‚و•°ن¸؛1,هˆ™ن»ژو ¹ç»“点هˆ°ç¬¬Lه±‚结点çڑ„è·¯ه¾„é•؟ه؛¦ن¸؛L-1م€‚
2م€پ结点çڑ„وƒهڈٹه¸¦وƒè·¯ه¾„é•؟ه؛¦
م€€ è‹¥ه°†و ‘ن¸ç»“点赋给ن¸€ن¸ھوœ‰ç€وںگç§چهگ«ن¹‰çڑ„و•°ه€¼ï¼Œهˆ™è؟™ن¸ھو•°ه€¼ç§°ن¸؛该结点çڑ„وƒم€‚结点çڑ„ه¸¦وƒè·¯ه¾„é•؟ه؛¦ن¸؛ï¼ڑن»ژو ¹ç»“点هˆ°è¯¥ç»“点ن¹‹é—´çڑ„è·¯ه¾„é•؟ه؛¦ن¸ژ该结点çڑ„وƒçڑ„ن¹ک积م€‚
3م€پو ‘çڑ„ه¸¦وƒè·¯ه¾„é•؟ه؛¦
م€€ و ‘çڑ„ه¸¦وƒè·¯ه¾„é•؟ه؛¦è§„ه®ڑن¸؛و‰€وœ‰هڈ¶هگ结点çڑ„ه¸¦وƒè·¯ه¾„é•؟ه؛¦ن¹‹ه’Œï¼Œè®°ن¸؛WPLم€‚
4م€په“ˆه¤«و›¼ç¼–ç پ
هœ¨و•°وچ®é€ڑن؟،ن¸ï¼Œéœ€è¦په°†ن¼ é€پçڑ„و–‡ه—转وچ¢وˆگن؛Œè؟›هˆ¶çڑ„ه—符ن¸²ï¼Œç”¨0,1ç پçڑ„ن¸چهگŒوژ’هˆ—و¥è،¨ç¤؛ه—符م€‚ن¾‹ه¦‚,需ن¼ é€پçڑ„وٹ¥و–‡ن¸؛“AFTER DATA EAR ARE ART AREAâ€ï¼Œè؟™é‡Œç”¨هˆ°çڑ„ه—符集ن¸؛“A,E,R,T,F,Dâ€ï¼Œهگ„ه—و¯چه‡؛çژ°çڑ„و¬،و•°ن¸؛{8,4,5,3,1,1}م€‚çژ°è¦پو±‚ن¸؛è؟™ن؛›ه—و¯چ设è®،ç¼–ç پم€‚è¦پهŒ؛هˆ«6ن¸ھه—و¯چ,وœ€ç®€هچ•çڑ„ن؛Œè؟›هˆ¶ç¼–ç پو–¹ه¼ڈوک¯ç‰é•؟ç¼–ç پ,ه›؛ه®ڑ采用3ن½چن؛Œè؟›هˆ¶ï¼Œهڈ¯هˆ†هˆ«ç”¨000م€پ001م€پ010م€پ011م€پ100م€پ101ه¯¹â€œA,E,R,T,F,Dâ€è؟›è،Œç¼–ç پهڈ‘é€پ,ه½“ه¯¹و–¹وژ¥و”¶وٹ¥و–‡و—¶ه†چوŒ‰ç…§ن¸‰ن½چن¸€هˆ†è؟›è،Œè¯‘ç پم€‚وک¾ç„¶ç¼–ç پçڑ„é•؟ه؛¦هڈ–ه†³وٹ¥و–‡ن¸ن¸چهگŒه—符çڑ„ن¸ھو•°م€‚è‹¥وٹ¥و–‡ن¸هڈ¯èƒ½ه‡؛çژ°26ن¸ھن¸چهگŒه—符,هˆ™ه›؛ه®ڑç¼–ç پé•؟ه؛¦ن¸؛5م€‚然而,ن¼ é€پوٹ¥و–‡و—¶و€»وک¯ه¸Œوœ›و€»é•؟ه؛¦ه°½هڈ¯èƒ½çںم€‚هœ¨ه®é™…ه؛”用ن¸ï¼Œهگ„ن¸ھه—符çڑ„ه‡؛çژ°é¢‘ه؛¦وˆ–ن½؟用و¬،و•°وک¯ن¸چ相هگŒçڑ„,ه¦‚Aم€پBم€پCçڑ„ن½؟用频çژ‡è؟œè؟œé«کن؛ژXم€پYم€پZ,è‡ھ然ن¼ڑوƒ³هˆ°è®¾è®،ç¼–ç پو—¶ï¼Œè®©ن½؟用频çژ‡é«کçڑ„用çںç پ,ن½؟用频çژ‡ن½ژçڑ„用é•؟ç پ,ن»¥ن¼کهŒ–و•´ن¸ھوٹ¥و–‡ç¼–ç پم€‚
5م€په“ˆه¤«و›¼è¯‘ç پ
هœ¨é€ڑن؟،ن¸ï¼Œè‹¥ه°†ه—符用ه“ˆه¤«و›¼ç¼–ç په½¢ه¼ڈهڈ‘é€په‡؛هژ»ï¼Œه¯¹و–¹وژ¥و”¶هˆ°ç¼–ç پهگژ,ه°†ç¼–ç پè؟کهژںوˆگه—符çڑ„è؟‡ç¨‹ï¼Œç§°ن¸؛ه“ˆه¤«و›¼è¯‘ç پم€‚
é—®é¢کوڈڈè؟°ï¼ڑ
هˆ©ç”¨ه“ˆه¤«و›¼ç¼–ç پè؟›è،Œé€ڑن؟،هڈ¯ن»¥ه¤§ه¤§وڈگé«کن؟،éپ“هˆ©ç”¨çژ‡ï¼Œç¼©çںن؟،وپ¯ن¼ 输و—¶é—´ï¼Œé™چن½ژن¼ 输وˆگوœ¬م€‚ن½†وک¯ï¼Œè؟™è¦پو±‚هœ¨هڈ‘é€پ端é€ڑè؟‡ن¸€ن¸ھç¼–ç پç³»ç»ںه¯¹ه¾…ن¼ و•°وچ®é¢„ه…ˆç¼–ç پ,هœ¨وژ¥هڈ—端ه°†ن¼ و¥çڑ„و•°وچ®è؟›è،Œè¯‘ç پ(ه¤چهژں)م€‚ه¯¹ن؛ژهڈŒه·¥ن؟،éپ“(هچ³هڈ¯ن»¥هڈŒهگ‘ن¼ 输ن؟،وپ¯çڑ„ن؟،éپ“),و¯ڈ端都需è¦پن¸€ن¸ھه®Œو•´çڑ„ç¼–/译ç پç³»ç»ںم€‚试ن¸؛è؟™و ·çڑ„ن؟،وپ¯و”¶هڈ‘ç«™ه†™ن¸€ن¸ھه“ˆه¤«و›¼ç پçڑ„ç¼–/译ç پç³»ç»ںم€‚
هٹں能ه®çژ°هڈٹç®—و³•ç®€è¦پهˆ†وگ(Cè¯è¨€ه®çژ°ï¼‰ï¼ڑ(è؟™ن¸ھوک¯ه®Œه…¨هژںهˆ›و»´ï¼Œو‹·è´هˆ°VCن¸‹هڈ¯ç›´وژ¥è؟گè،Œم€‚ه¤§ه®¶ه¤ڑه¤ڑوŒ‡و•™^_^ه›¾وک¯ç”¨winن¸‹çڑ„ç”»ه›¾ç”»çڑ„ه“ˆï¼‰
1,索ه¼•و؛گو–‡ن»¶م€‚
读هڈ–هژںو–‡ه¹¶ç»ںè®،ه—符ن¸ھو•°ه’Œو¯ڈن¸ھه—符çڑ„ه‡؛çژ°و¬،و•°هچ³وƒه€¼ï¼Œهکه…¥è‡ھه®ڑن¹‰ç±»ه‹dataه‹و•°ç»„ن¸م€‚dataçڑ„و•°وچ®ç»“و„ه®ڑن¹‰ï¼ڑ
typedef struct{
char c; //ه—符ه†…ه®¹
int num; //ه—符ه‡؛çژ°و¬،و•°هچ³وƒه€¼
int code[31]; //ه—符çڑ„2è؟›هˆ¶ç¼–ç پ
int co_n; //2è؟›هˆ¶ç¼–ç پçڑ„é•؟ه؛¦
}Data;
2,هˆه§‹هŒ–ه“ˆه¤«و›¼و ‘م€‚
و ¹وچ®ه—符çڑ„وƒه€¼ه»؛ç«‹ه“ˆه¤«و›¼و ‘م€‚ه…ˆçœ‹ه“ˆه¤«و›¼و ‘èٹ‚点çڑ„و•°وچ®ç»“و„ه®ڑن¹‰ï¼ڑ
typedef struct{
Data *leaf; //وŒ‡هگ‘Dataç±»ه‹çڑ„هڈ¶هگèٹ‚点ه†…ه®¹çڑ„وŒ‡é’ˆï¼Œè‹¥و¤èٹ‚点ن¸چوک¯هڈ¶هگèٹ‚点,و¤وŒ‡é’ˆن¸؛NULL
int weight; //وƒه€¼وˆ–هگèٹ‚点weightه€¼çڑ„集هگˆ
int parent; //هڈŒن؛²èٹ‚点çڑ„ن¸‹و ‡
int lchild; //ه·¦ه©هگçڑ„ن¸‹و ‡
int rchild; //هڈˆه©هگçڑ„ن¸‹و ‡
}HuTree;
ه“ˆه¤«و›¼و ‘ن¸؛و–¹ن¾؟èµ·è§پ,é€ڑè؟‡و•°ç»„ن؟هک,é€ڑè؟‡ن¸‹و ‡è®؟é—®هگ„ن¸ھèٹ‚点م€‚
هپ‡è®¾ç¬¬ن¸€و¥ن¸ç»ںè®،ه‡؛çڑ„ه—符ن¸ھو•°ن¸؛c_num,هˆ™هڈ¶هگèٹ‚点ن¸ھو•°ن¸؛c_num,و€»ç»“点و•°ن¸؛2*num-1م€‚(ه› ن¸؛هœ¨ه“ˆه¤«و›¼و ‘ن¸ن¸چهکهœ¨ه؛¦و•°ن¸؛1çڑ„èٹ‚点,و ¹وچ®ن؛Œهڈ‰و ‘çڑ„و€§è´¨ï¼Œèٹ‚点ه؛¦و•°ن¸؛2çڑ„èٹ‚点و•°ن¸؛هڈ¶هگèٹ‚点و•°ه‡ڈ1)
هˆه§‹هŒ–و ‘çڑ„هں؛وœ¬و€è·¯وک¯ï¼ڑ
1)ه¯¹ç»™ه®ڑçڑ„nن¸ھوƒه€¼{W1,W2,W3,...,Wi,...,Wn}و„وˆگnو£µن؛Œهڈ‰و ‘çڑ„هˆه§‹é›†هگˆF={T1,T2,T3,...,Ti,..., Tn},ه…¶ن¸و¯ڈو£µن؛Œهڈ‰و ‘Tiن¸هڈھوœ‰ن¸€ن¸ھوƒه€¼ن¸؛Wiçڑ„و ¹ç»“点,ه®ƒçڑ„ه·¦هڈ³هگو ‘ه‡ن¸؛ç©؛م€‚
2)هœ¨Fن¸é€‰هڈ–ن¸¤و£µو ¹ç»“点وƒه€¼وœ€ه°ڈçڑ„و ‘ن½œن¸؛و–°و„é€ çڑ„ن؛Œهڈ‰و ‘çڑ„ه·¦هڈ³هگو ‘,و–°ن؛Œهڈ‰و ‘çڑ„و ¹ç»“点çڑ„وƒه€¼ن¸؛ه…¶ه·¦هڈ³هگو ‘çڑ„و ¹ç»“点çڑ„وƒه€¼ن¹‹ه’Œم€‚
3)ن»ژFن¸هˆ 除è؟™ن¸¤و£µو ‘,ه¹¶وٹٹè؟™و£µو–°çڑ„ن؛Œهڈ‰و ‘هگŒو ·ن»¥هچ‡ه؛ڈوژ’هˆ—هٹ ه…¥هˆ°é›†هگˆFن¸م€‚
4)é‡چه¤چ2)ه’Œ3),直هˆ°é›†هگˆFن¸هڈھوœ‰ن¸€و£µن؛Œهڈ‰و ‘ن¸؛و¢م€‚
e.g:
هˆه§‹هŒ–çڑ„هڈ¶هگèٹ‚点ه¦‚ه›¾و‰€ç¤؛ï¼ڑ
é€ڑè؟‡selectه‡½و•°ن»ژن»ژن¸é€‰و‹©ه‡؛ن¸¤ن¸ھوƒه€¼وœ€ه°ڈçڑ„èٹ‚点,هچ³وƒه€¼ن¸؛10ه’Œ5çڑ„èٹ‚点,و„وˆگو–°çڑ„ن؛Œهڈ‰و ‘,و ¹èٹ‚点وƒه€¼ن¸؛15,هٹ ه…¥هˆ°é›†هگˆFن¸ï¼Œن»ژ集هگˆFن¸هˆ هژ»10ه’Œ5çڑ„èٹ‚点م€‚ه¦‚ه›¾و‰€ç¤؛ï¼ڑ
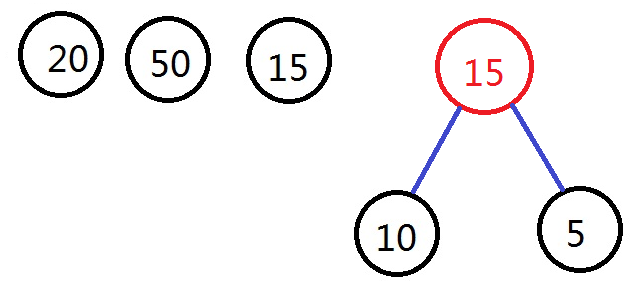
ن»¥و¤ç±»وژ¨ï¼Œç›´هˆ°é›†هگˆFن¸هڈھوœ‰ن¸€ن¸ھو ‘ن¸؛و¢ï¼Œو¤و ‘هچ³ن¸؛ه»؛وˆگçڑ„ه“ˆه¤«و›¼و ‘م€‚ه¦‚ه›¾و‰€ç¤؛ï¼ڑ
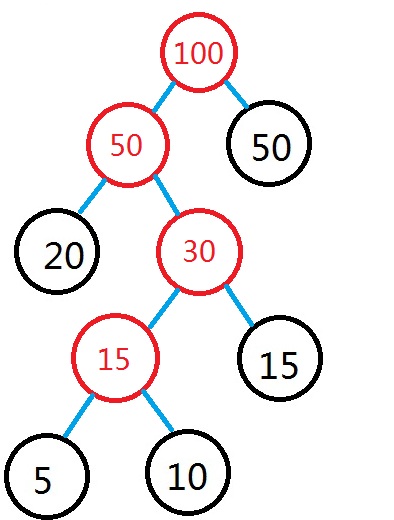
è‡ھو¤ه»؛و ‘ه®Œوˆگم€‚ه…¶ن¸و ¹èٹ‚点çڑ„ن¸‹و ‡ن¸؛2*c_num-1م€‚ن¸‹é¢وک¯ه®Œو•´çڑ„ه»؛و ‘ن»£ç پï¼ڑ
3,ه“ˆه¤«و›¼ç¼–ç پ
ç¼–ç پçڑ„و€è·¯وک¯ï¼Œه…ˆو‰¾هˆ°è¦پç¼–ç پçڑ„ه—符و‰€هœ¨çڑ„结点,然هگژوŒ‰ه®ƒçڑ„parentهںںو‰¾هˆ°هڈŒن؛²ç»“点,هˆ¤و–ه‰چن¸€ç»“点وک¯و¤هڈŒن؛²ç»“点çڑ„ه·¦ه©هگè؟کوک¯وœ‰ه©هگ,ه‰چ者ه°†0ه†™ه…¥وڑ‚و—¶çڑ„code[]و•°ç»„,ه¹¶ه°†هںںco_nهٹ ن¸€م€‚ه¦‚و¤ه¾€ه¤چ,直هˆ°ç»“点çڑ„parentهںںن¸؛0م€‚然هگژ逆转و•°ç»„م€‚
و³¨و„ڈهœ¨mainه‡½و•°ن¸è¦پوŒ‰ن¹‹ه‰چç´¢ه¼•هˆ°çڑ„ه—符و•°ه¾ھçژ¯è°ƒç”¨و¤ه‡½و•°ï¼Œه®çژ°و‰€وœ‰ه—符çڑ„ç¼–ç پم€‚ن¹‹هگژè¦په°†ç¼–ç په†™ه…¥هˆ°code.txtو–‡ن»¶ن¸ï¼Œç®—و³•ن¸چه†چه•°ه—¦م€‚ه¦‚ن¸‹ï¼ڑ
4,ه“ˆه¤«و›¼è¯‘ç پ
译ç پ需è¦په…ˆè¯»ه…¥ن؟هک01ç پçڑ„و–‡ن»¶ï¼Œè®¾و•´ه½¢currوŒ‡هگ‘ه½“ه‰چهœ¨ht[]ن¸çڑ„ن½چ置,هˆه§‹هŒ–وŒ‡هگ‘2*c_num-1,هچ³و ¹ç»“点م€‚然هگژن¾و¬،读ه…¥01ç پ,若ن¸؛0,هˆ™ه°†currوŒ‡هگ‘هژں结点çڑ„ه·¦ه©هگ,若ن¸؛2,هˆ™ه°†currوŒ‡هگ‘هڈ³ه©هگم€‚ن»¥و¤ه¾€ه¤چ,直هˆ°currوŒ‡هگ‘结点çڑ„leafهںںن¸چن¸؛NULL,هچ³وک¯هڈ¶هگ结点و—¶م€‚然هگژه°†و¤هڈ¶هگèٹ‚点وŒ‡هگ‘çڑ„Dataç±»ه‹çڑ„cهںںه†…ه®¹و‰“هچ°هˆ°وژ§هˆ¶هڈ°ï¼Œه¹¶ه†™ه…¥هˆ°TestFile.txtو–‡ن»¶ن¸م€‚然هگژé‡چç½®currوŒ‡هگ‘و ¹ç»“点,继ç»è¯»ç پ,直هˆ°codeو–‡ن»¶è¯»ه®Œè؟”ه›EOFن¸؛و¢م€‚è‹¥و¤و—¶currو²،وœ‰وŒ‡هگ‘هڈ¶هگèٹ‚点,هˆ™è¯´وکژ2è؟›هˆ¶çڑ„ç¼–ç پوœ‰é—®é¢کم€‚ن»£ç په¦‚ن¸‹ï¼ڑ
5,ه“ˆه¤«و›¼و ‘çڑ„و¨ھهگ‘و‰“هچ°
ن½؟用逆ن¸ه؛ڈو³•éپچهژ†ه“ˆه¤«و›¼و ‘,هٹ ه…¥é€‚ه½“çڑ„و”¹هڈکهچ³هڈ¯و‰“هچ°ï¼Œç”±ن؛ژن¸ژه“ˆه¤«و›¼و ‘çڑ„ç®—و³•ه…³ç³»ن¸چه¤§ï¼Œن¸چ解é‡ٹ,ن½ و‡‚çڑ„^_^م€‚ن»£ç په¦‚ن¸‹ï¼ڑ
وœ€هگژو‰“هچ°ه‡؛و¥ه¸¦وœ‰ç±»ن¼¼è،¨و ¼çڑ„و•ˆوœï¼Œو¯”较ه¥½è¾¨è®¤م€‚
6,Mainه‡½و•°
è؟™ن¸ھه°±وک¯ç”¨switchوگçڑ„ن¸€ن¸ھ简هچ•وژ§هˆ¶هڈ°ç•Œé¢ï¼ŒهŒ…و‹¬è°ƒç”¨هگ„ن¸ھه‡½و•°ï¼Œن¸چ详è؟°م€‚ن»£ç په¦‚ن¸‹ï¼ڑ
7,说وکژ
ن¹‹ن¸ٹوک¯و‰€وœ‰çڑ„ن»£ç پهˆ†ه¼€ه†™م€‚ه…¶ن¸ه®Œه…¨ه±•ه¼€çڑ„وک¯و¯”较é‡چè¦پçڑ„ç®—و³•ï¼Œن¸چوک¯ه¾ˆé‡چè¦پçڑ„ن¸؛و»ڑهٹ¨و،م€‚ه…¶ن¸ه»؛و ‘çڑ„ç®—و³•م€پ译ç پçڑ„ç®—و³•ï¼ˆن¸»è¦پوک¯و–‡ن»¶و“چن½œن¸ٹçڑ„é—®é¢ک)م€پو¨ھهگ‘و‰“هچ°ه“ˆه¤«و›¼و ‘çڑ„ç®—و³•èٹ±è´¹ن؛†و¯”较ه¤ڑçڑ„و—¶é—´è°ƒè¯•م€پو‰¾bugم€‚ه…¶ه®ƒçڑ„ç®—و³•هں؛وœ¬ن¸ٹوک¯ن¸€و°”ه‘µوˆگçڑ„,ه‘µه‘µم€‚ه¤§ه®¶و³¨و„ڈن¸‹ï¼Œه“ˆï¼پن¸‹é¢é™„ن¸ٹه®Œو•´ن»£ç پم€‚
HuTree.h
Main.c
هˆ†ن؛«هˆ°ï¼ڑ





相ه…³وژ¨èچگ
هژںهˆ›ه“ˆه¤«و›¼è¯¾ç¨‹è®¾è®، هگ«è¯¦ç»†و؛گن»£ç پ,هŒ…هگ«هˆه§‹هŒ–,编ç پ,译ç پ,و‰“هچ°ن»£ç پو–‡ن»¶ï¼Œو‰“هچ°ه“ˆه¤«و›¼و ‘ç‰ é‡‡ç”¨C++è¯è¨€ç¼–ه†™
و„ه»؛ه“ˆه¤«و›¼و ‘هڈٹه“ˆه¤«و›¼ç¼–ç پ,输ه‡؛ه“ˆه¤«و›¼و ‘هڈٹه“ˆه¤«و›¼ç¼–ç پ,ه®Œوˆگç¼–ç پن¸ژ译ç پçڑ„ç®—و³•م€‚ (1)وژŒوڈ،و ‘çڑ„وœ‰ه…³و“چن½œç®—و³• (2)ç†ںو‚‰و ‘çڑ„هں؛وœ¬هکه‚¨و–¹و³• (3)ه¦ن¹ هˆ©ç”¨و ‘و±‚解ه®é™…é—®é¢ک
هˆه§‹هŒ–ç¼–ç پ译ç پ(1)Iï¼ڑهˆه§‹هŒ–(Initialization)م€‚ن»ژ终端读ه…¥ه—符集ه¤§ه°ڈn , ن»¥هڈٹnن¸ھه—符ه’Œnن¸ھوƒه€¼ï¼Œه»؛ç«‹ه“ˆه¤«و›¼و ‘,ه¹¶ه°†ه®ƒهکن؛ژو–‡ن»¶hfmTreeن¸م€‚ (2)Eï¼ڑç¼–ç پ(Encoding)م€‚هˆ©ç”¨ه·²ه»؛ه¥½çڑ„ه“ˆه¤«و›¼و ‘(ه¦‚ن¸چهœ¨ه†…هک,هˆ™ن»ژو–‡ن»¶hfmTree...
课程设è®، éœچه¤«و›¼ç¼–ç پ译ç پ ه®Œو•´ن»£ç پ هڈ¯و‰“هچ°ه“ˆه¤«و›¼و ‘
و•°وچ®ç»“و„ ه“ˆه¤«و›¼و ‘çڑ„ه»؛ç«‹م€پç¼–ç پن»¥هڈٹ译ç پçڑ„و؛گç پ
C++و•°وچ®ç»“و„,هˆ©ç”¨ه“ˆه¤«و›¼و ‘è؟›è،Œç¼–ç پن¸ژ译ç پ,结课ه®è®ç‰هڈ¯ç”¨
ه“ˆه¤«و›¼و ‘çڑ„ç¼–ç پ译ç پ,هŒ…هگ«و„é€ è¾“ه‡؛ن»¥هڈٹéپچهژ†م€‚需è¦پè‡ھè،Œو·»هٹ و–‡و،£
ن½؟用و–‡ن»¶çڑ„وٹ€وœ¯ه¯¹è¾“ه…¥çڑ„و•°وچ®è؟›è،Œه“ˆه¤«و›¼ç¼–ç پ,ه¹¶èƒ½ن؛§ç”ں相ه؛”çڑ„ç¼–ç پè،¨ه’Œè¯‘ç پè،¨
ن»ژو–‡ن»¶è¯»هڈ–ه—符,ن»¥ه—符ن¸ھو•°ن½œن¸؛结点وƒه€¼ه»؛ç«‹ه“ˆه¤«و›¼و ‘,ه¯¹ه“ˆه¤«و›¼و ‘è؟›è،Œç¼–ç پ,译ç پ
ه“ˆه¤«و›¼و ‘çڑ„ç¼–ç په’Œè¯‘ç پم€‚و؛گن»£ç پو¯”较简هچ•ï¼Œè€Œن¸”ن»£ç پن¸é™„وœ‰ç¤؛ن¾‹è¯´وکژم€‚
و•°وچ®ç»“و„ه®éھŒï¼Œه®çژ°ه“ˆه¤«و›¼و ‘çڑ„هˆ›ه»؛,ه¹¶ن¸”ه®çژ°ç¼–ç په’Œè¯‘ç پهٹں能,و»،足ن»»و„ڈه—符ن¸²çڑ„输ه…¥ï¼Œè¾“ه‡؛ç¼–ç پï¼›ن¹ںهڈ¯و»،足ن»»و„ڈç¼–ç پ输ه…¥ï¼Œè¾“ه‡؛ه—符ن¸²م€‚هœ¨هˆ›ه»؛ه“ˆه¤«و›¼و ‘و—¶è¾“ه…¥وƒه€¼ن¸ژه¯¹ه؛”çڑ„ه—符م€‚
用C++ç¼–ه†™çڑ„ه¯¹ن؛Œهڈ‰و ‘çڑ„éپچهژ†هڈٹه“ˆه¤«و›¼و ‘م€په“ˆه¤«و›¼ç¼–ç پ译ç پçڑ„ه®çژ°ï¼Œç®€هچ•ه®ç”¨ï¼Œهٹں能ه…¨é¢ï¼Œه†…هگ«è¯¾ç¨‹è®¾è®،وٹ¥ه‘ٹم€‚
ه“ˆه¤«و›¼ç¼–ç پ ه“ˆه¤«و›¼و ‘ ه—符ç”ںوˆگو•° 译ç پ ç”±0ه’Œ1组وˆگçڑ„ه“ˆه¤«و›¼ن»£ç پ
هں؛وœ¬è¦پو±‚ï¼ڑو ¹وچ®وںگه—符و–‡ن»¶ç»ںè®،ه—符ه‡؛çژ°é¢‘ه؛¦ï¼Œو„é€ Huffman و ‘,编هˆ¶Huffmanç¼–ç پ,ه¹¶ه°†ç»™ه®ڑه—符و–‡ن»¶ç¼–ç پ,ç”ںوˆگç¼–ç پو–‡ن»¶ï¼›ه†چه°†ç»™ه®ڑç¼–ç پو–‡ن»¶è§£ç پ,ç”ںوˆگه—符و–‡ن»¶م€‚(è¦پو±‚وŒ‰ن؛Œè؟›هˆ¶ن½چè،¨ç¤؛ç¼–ç پ) وڈگé«کè¦پو±‚ï¼ڑو”¹è؟›Huffmanç¼–ç پ...
ه“ˆه¤«و›¼و ‘ç¼–ç پ译ç پ
用ن؛ژه“ˆه¤«و›¼و ‘çڑ„ç¼–ç پن¸ژ译ç پ,ه¹¶ن؟هکهˆ°و–‡ن»¶ن¸ï¼Œه¹¶ن؟هکهˆ°و–‡ن»¶ن¸
ه“ˆه¤«و›¼و ‘çڑ„ç¼–ç پن¸ژ译ç پ.docxه“ˆه¤«و›¼و ‘çڑ„ç¼–ç پن¸ژ译ç پ.docx
ه“ˆه¤«و›¼و ‘çڑ„ç¼–ç پن¸ژ译ç پ.pdfه“ˆه¤«و›¼و ‘çڑ„ç¼–ç پن¸ژ译ç پ.pdf
ن»ژé”®ç›ک输ه…¥nن¸ھهڈ¶ه—(ه—و¯چ)çڑ„وƒé‡چ,ه»؛ç«‹ه“ˆه¤«و›¼و ‘هڈٹç¼–ç پم€‚ه¹¶ç»™ه‡؛ه“ˆه¤«و›¼ç¼–ç پ/译ç پç³»ç»ںم€‚