问题:
How can anagrams result from sequences of stack operations? There are two sequences of stack operators which can convert TROT to TORT:
[
i i i i o o o o
i o i i o o i o
]
whereistands for Push andostands for Pop. Your program should, given pairs of words produce sequences of stack operations which convert the first word to the second.
Input
The input will consist of several lines of input. The first line of each pair of input lines is to be considered as a source word (which does not include the end-of-line character). The second line (again, not including the end-of-line character) of each pair is a target word. The end of input is marked by end of file.
Output
For each input pair, your program should produce a sorted list of valid sequences ofiandowhich produce the target word from the source word. Each list should be delimited by
[
]
and the sequences should be printed in "dictionary order". Within each sequence, eachiandois followed by a single space and each sequence is terminated by a new line.
Process
A stack is a data storage and retrieval structure permitting two operations:
Push - to insert an item and
Pop - to retrieve the most recently pushed item
We will use the symboli(in) for push ando(out) for pop operations for an initially empty stack of characters. Given an input word, some sequences of push and pop operations are valid in that every character of the word is both pushed and popped, and furthermore, no attempt is ever made to pop the empty stack. For example, if the word FOO is input, then the sequence:
| i i o i o o |
is valid, but |
| i i o |
is not (it's too short), neither is |
| i i o o o i |
(there's an illegal pop of an empty stack) |
Valid sequences yield rearrangements of the letters in an input word. For example, the input word FOO and the sequencei i o i o oproduce the anagram OOF. So also would the sequencei i i o o o. You are to write a program to input pairs of words and output all the valid sequences ofiandowhich will produce the second member of each pair from the first.
Sample Input
madam
adamm
bahama
bahama
long
short
eric
rice
[
i i i i o o o i o o
i i i i o o o o i o
i i o i o i o i o o
i i o i o i o o i o
]
[
i o i i i o o i i o o o
i o i i i o o o i o i o
i o i o i o i i i o o o
i o i o i o i o i o i o
]
[
]
[
i i o i o i o o
]
通过栈的进栈、出栈操作描述由第一个源字符串转换到目的字符串。i表示进栈,o表示出栈。输出所有的可能,并且结果按字典顺序排列。anagram意为回文构词法。若源字符串无法转换为目的字符串,则不显示结果。
比如:madam转换为adamm:
m进栈,a进栈,d进栈,a进栈,a出栈,d出栈,a出栈,m进栈,m出栈,m出栈。即显示结果为:i i i i o o o i o o
这只是一种情况,要求显示出所有的情况。结果由一对"["、“]”包住。
通过递归调用过程anagram解决问题。
函数anagram的接口为:
void anagram(char *p_st, int top, char *p_res, int num, int si, int ti);
p_st指向当前的栈,top指向当前入栈位置,即栈顶元素为p_st[top-1]。p_res指向存储结果的字符串,num为下一个结果的位置。si为当前源字符串的搜索位置,ti为当前目的字符串的搜索位置。
源字符串source和目的字符串target为全局变量。
本过程一开始要对栈和结果字符串进行复制,否则无法得到多个结果且会产生混乱。
流程图为:
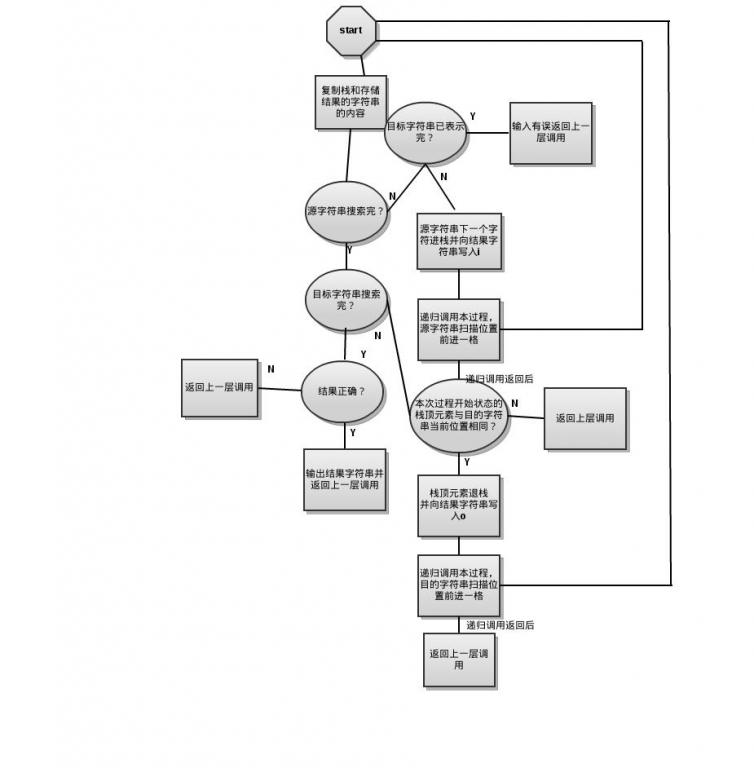
优先进栈,写入“i”,并递归调用,之后返回后再看是否原栈顶元素是否与当前目的字符串搜索位置匹配,再在合适地方写入“o”,然后递归调用。每一次过程调用先考虑“i”的情况再考虑“o”的情况保证了输出结果按字典排序输出。
基本上此过程有3个主要过程,检验是否产生结果,进栈并处理,出栈并处理。
在Ubuntu下没有找到一个好用的画图工具,于是使用了一个在线绘制流程图的app:Gliffy(http://www.gliffy.com/)。非常不错!
代码(gcc)
分享到:




相关推荐
深度搜索 回溯 int main { string s1 s2; while cin >> s1 >> s2 { count 0; cout << "[" << endl; if s1 length s2 length BackTrake s1 s2 ;... [更多]
zoj_1004.cpp 求单词字母进出栈后能形成目标串的进出方案 广度优先搜索求解
问题:枫教授在一所大学教数学,他发现了一个函数,用于获得一个表达式的操作数的目的,函数命名op(i,e)可以描述如下:
zoj 题库 详细解答 解题代码 acm
ZOJ解题报告ZOJ解题报告ZOJ解题报告ZOJ解题报告
zoj题目简单归类zoj题目简单归类zoj题目简单归类
acm中zoj1002的可运行C++程序
acm 新手必备 浙大 解答 代码库 zoj zju
包含了zoj700多道题目的源代码,在做题时可以参考
能AC 通过的c++代码,包括zoj1002,1091,1789
Problem Arrangement zoj 3777
ZOJ题目答案源码
一个非常非常非常非常实用的zoj结题代码
学习ACM程序设计的朋友一定要看,这是训练必备的POJ ZOJ题目分类及解题思路
Determine the Price For the manager of a theatre, setting the price of a ticket is a rather delicate matter. Suppose that a theatre has n () seats, and that if you give away the tickets for free, all ...
ZOJ1805代码
zoj 1003 c语言的,要写这么多描述吗。。
本代码是zoj上AC的1951的代码,把双重循环简化为O(n),不过素数判断的改进还不够
zoj1027解题指南和代码,还不错,是学校培训给的。
浙大ZOJ题目分类,可以让你更方便快速锁定那你想要联系的题目,是自己快速提高·